Projektverlaufsplanung
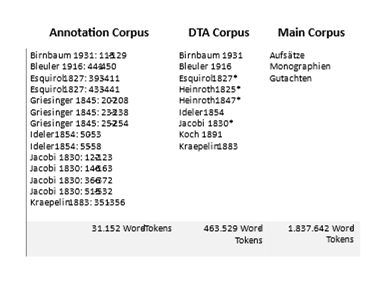
In der ersten Projektphase geht es um den Aufbau umfassender Gesamt- sowie themenspezifischer Spezialkorpora (building a corpus). Die Projektstandorte Heidelberg und Paderborn arbeiten unabhängig voneinander an dem Aufbau ihrer jeweiligen Korpora. Dabei geht es dem Projektstandort Paderborn vor allem um eine diachrone Erfassung zentraler psychiatrischer Fachtexte aus Lehrbüchern sowie Fachzeitschriften vom 19. bis zum 20. Jahrhundert. Methodisch unterschieden wird hinsichtlich des Aufbaus a) eines Gesamtkorpus (main corpus), in das alle Texte einfließen (bisher ca. 2 Mio. Tokens), b) eines DTA-Korpus (dta corpus), bestehend auf kanonischen Lehrbüchern, das im Laufe des Projektverlaufs ins DTA eingepflegt werden soll sowie c) eines Annotationskorpus (annotation corpus), das der explorativen Aufarbeitung charakteristischer Sprachhandlung in diesen Texten dient.
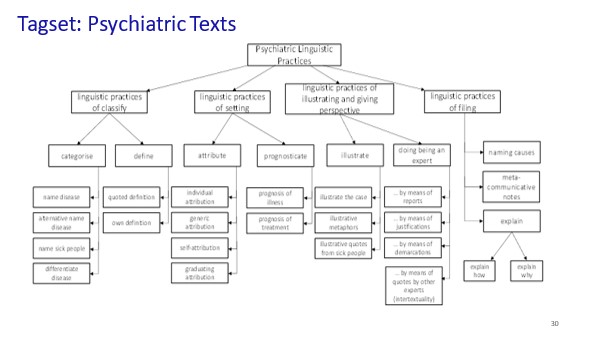
Zusammen mit dem Korpusaufbau wird eines der Spezialkorpora (Annotationskorpus) zur manuellen, explorativen Annotation genutzt (exploratory manual annotation). Die Annotationen dienen der orientierenden Erfassung zentraler projektrelevanter Phänomene um die Frage nach Sprachhandlungen der Bestimmung, des Erfassens, des Ausgleichens sowie Reflektierens von Unterbestimmtheit im Rahmen textgattungsspezifischer Sprachhandlungen. Dazu wurde ein eigenes Tagset entwickelt. Projektziel ist das Erstellen und Veröffentlichen dazugehöriger Guidelines.
Nach Abschluss der explorativen manuellen Annotation sollen die daraus gewonnenen Ergebnisse durch die Nutzung (halb)automatisierter Quantifizierungen abgesichert, abgeglichen sowie erweitert werden ((semi) automatic quantification).
Eine zweite Projektphase wird durch die gemeinsame Recherche nach sowie Aufarbeitung von Fällen eingeleitet (linguistic analysis of (legal) cases). Ziel ist es, 2-3 historische sowie gegenwärtige Fälle auf sowohl psychiatrischer (durch z.B. psychiatrische Gutachten) als auch juristischer (durch z.B.: Gerichtsurteile) Ebene erfassen sowie analysieren zu können. Auf Basis der gewonnenen Erkenntnisse aus der qualitativen Annotation sowie der quantitativen Korpusauswertung soll die Interdependenz, Bezogenheit sowie die Unterschiedlichkeit der Aufnahme und Verarbeitung von Unterbestimmtheit anhand bestimmter Begriffe und vermittels bestimmter Sprachhandlungen holistisch durch close reading Verfahren aufgearbeitet werden. Währenddessen kommt es auch zu einer stärkeren Zusammenarbeit beider Projektstandorte.